The Vision Transformer architecture
The Vision Transformer has been developed by Google and is a good example of how easy it is to adapt the Transformer architecture for any data type.

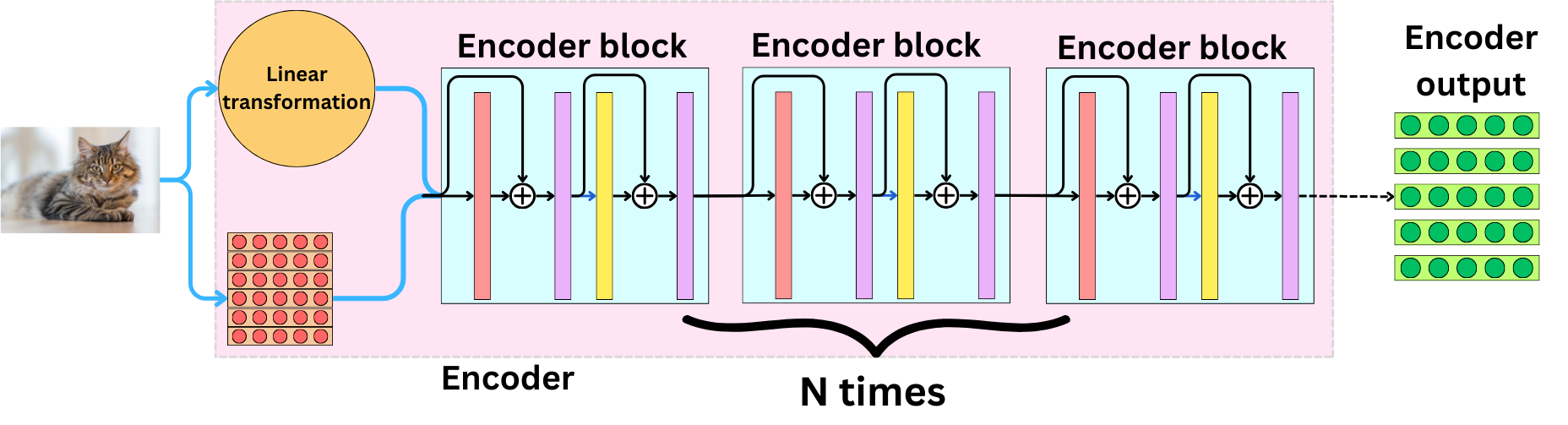
The idea is to break down the input image into small patches and transform each of the patches into an input vector for the Transformer model. It can be a simple linear transformation such that we obtain vectors in the right format.
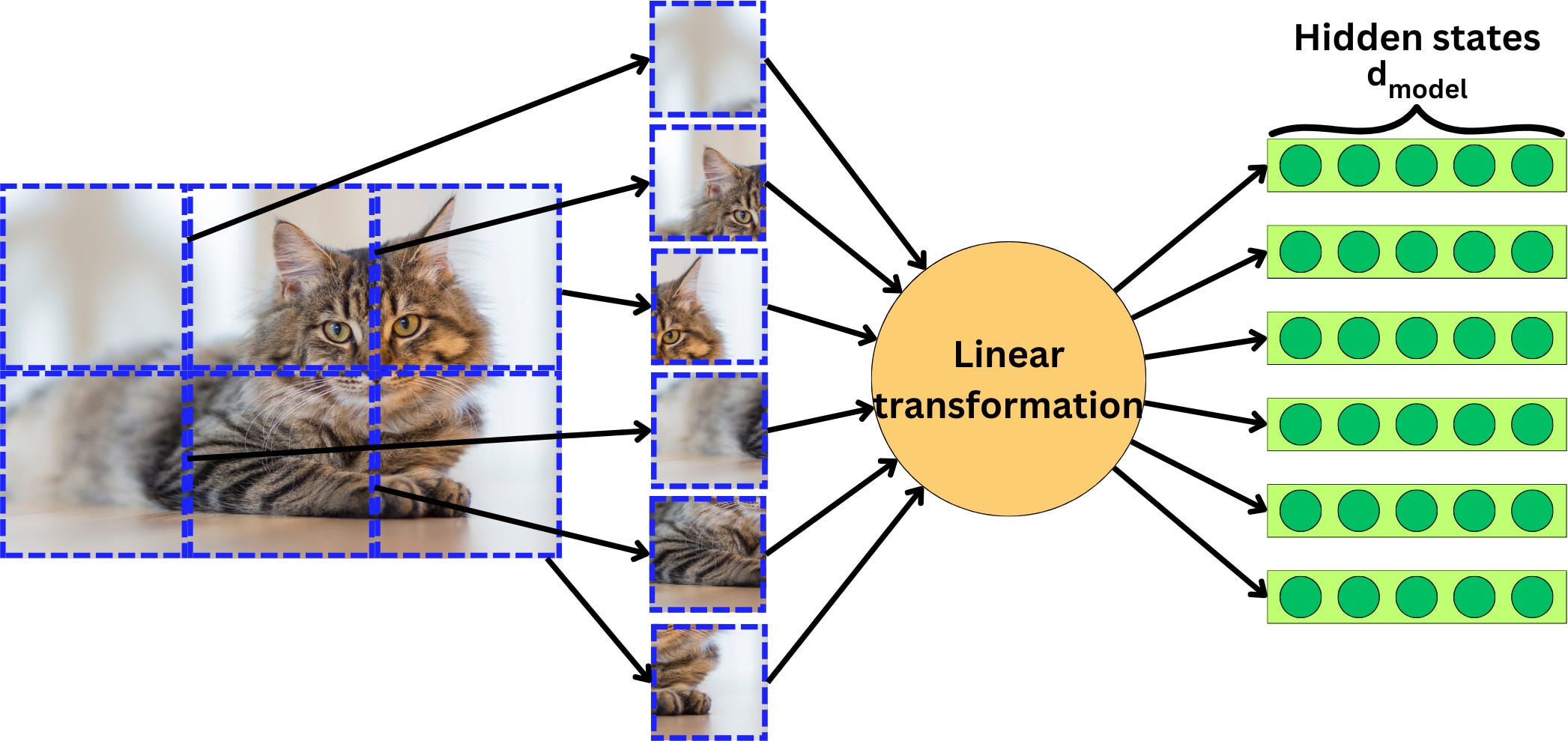
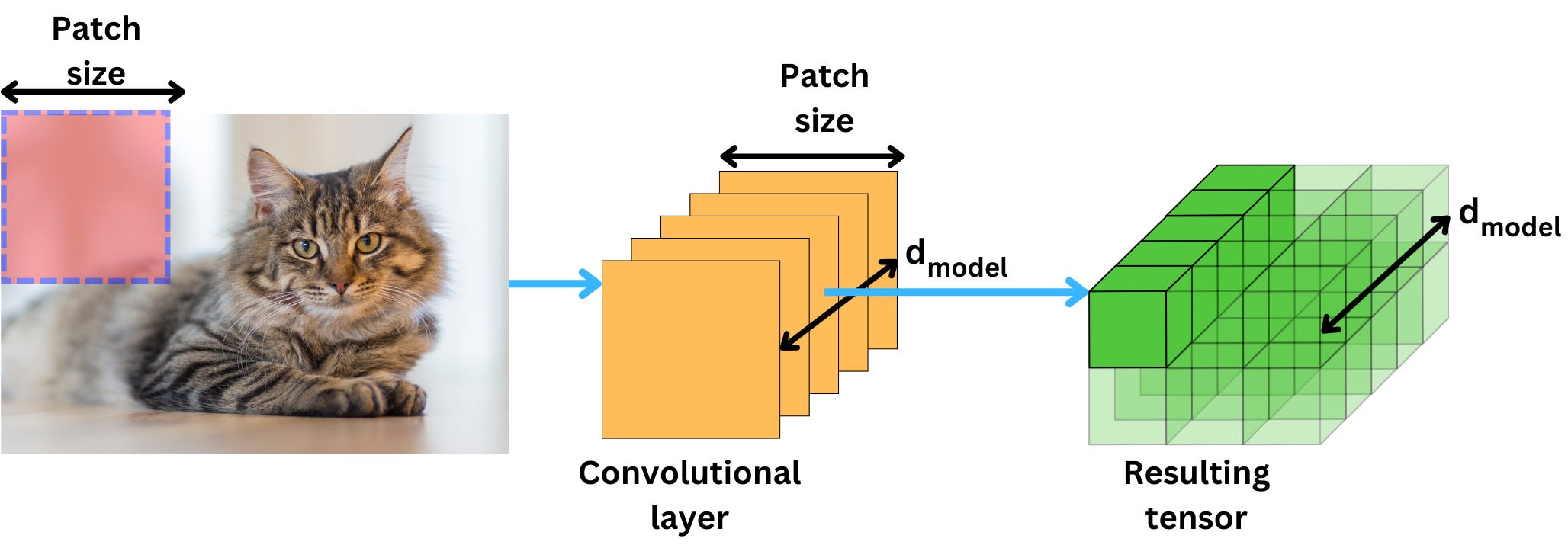
If we use a convolution layer as a linear transformation, we can process the whole image in one-shot. The convolutional layer just needs to have the right dimension to get the vectors with the right format.
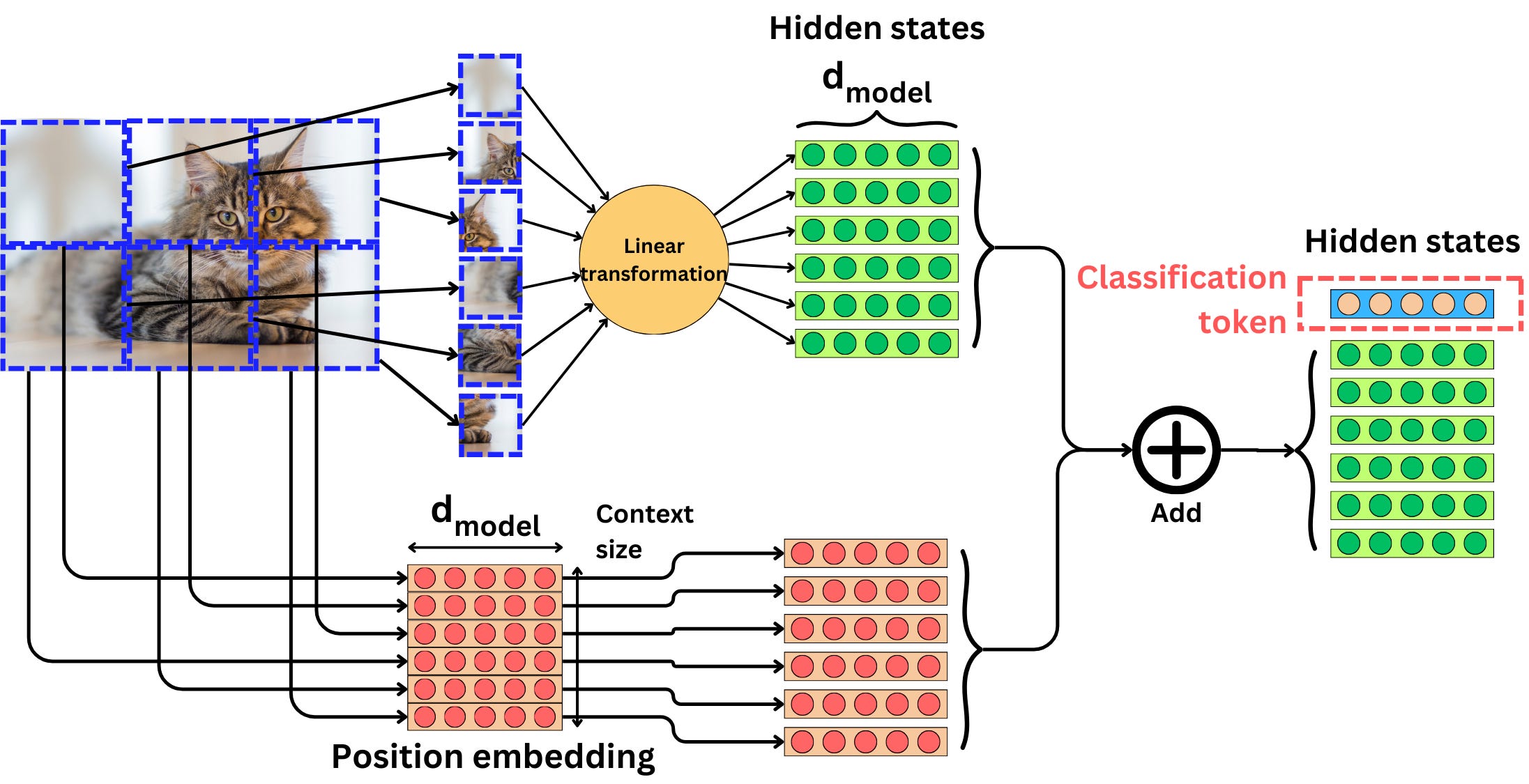
Once we transform the image into vectors, the process is very similar to the one we saw with the typical encoder transformer. We use a position embedding to capture the position of the patches, and we add it to the vectors coming from the convolutional layer. It is typical to add an additional learnable vector if we want to perform a classification task.
After that, we can feed those resulting vectors to the first encoder block.
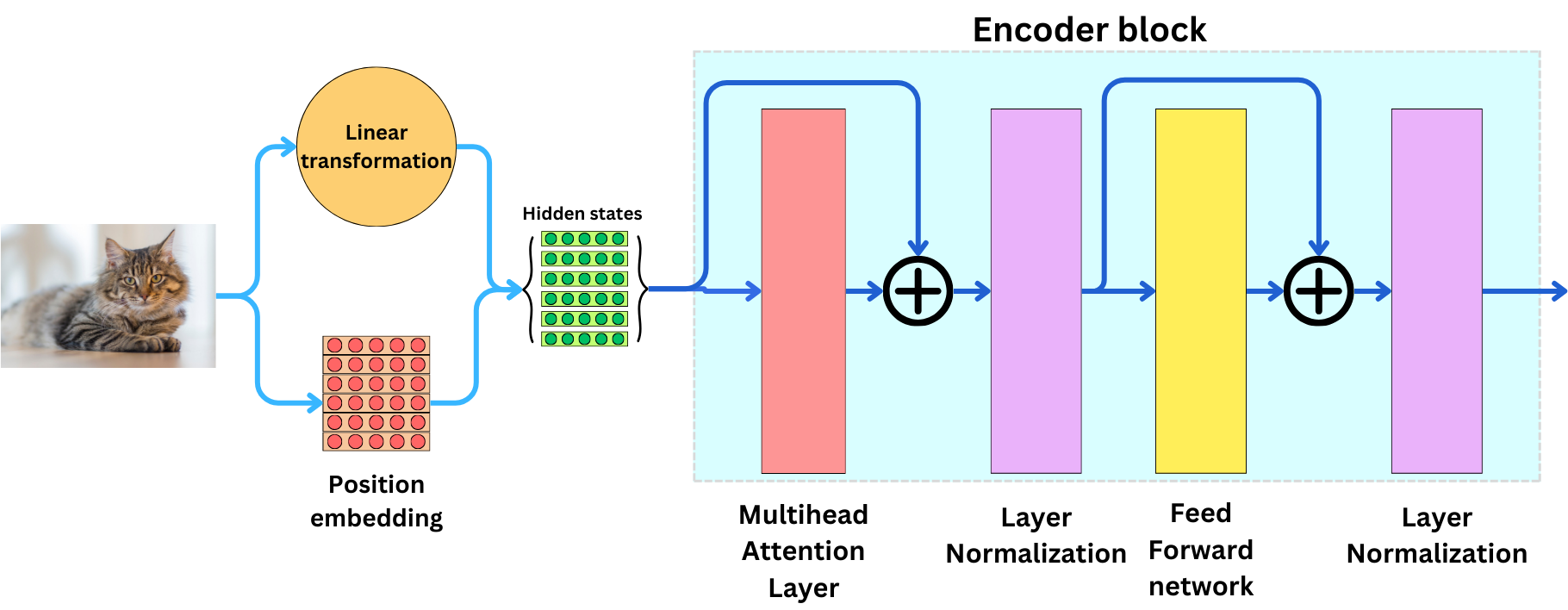
We add as many encoder blocks in the encoder as we need. In the end, we obtain the encoder output.
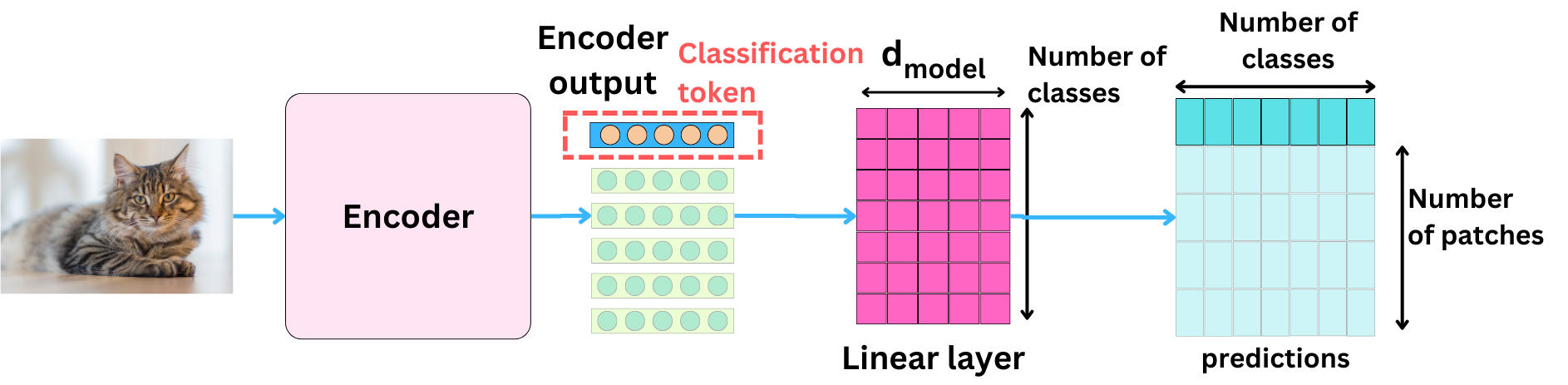
A linear layer is used as the prediction head, and it projects from the hidden states dimension to the prediction vectors dimension. In the case of classification, we only use the first vector that corresponds to the classification token we added at the beginning of the model.
0 comments