Beam Search generation
In the case of the greedy search and the multinomial sampling, we iteratively look for the next best token conditioned on the prompt and the previous tokens.

But those are not the probabilities we care about. We care about generating the best sequence of tokens conditioned on a specific prompt.
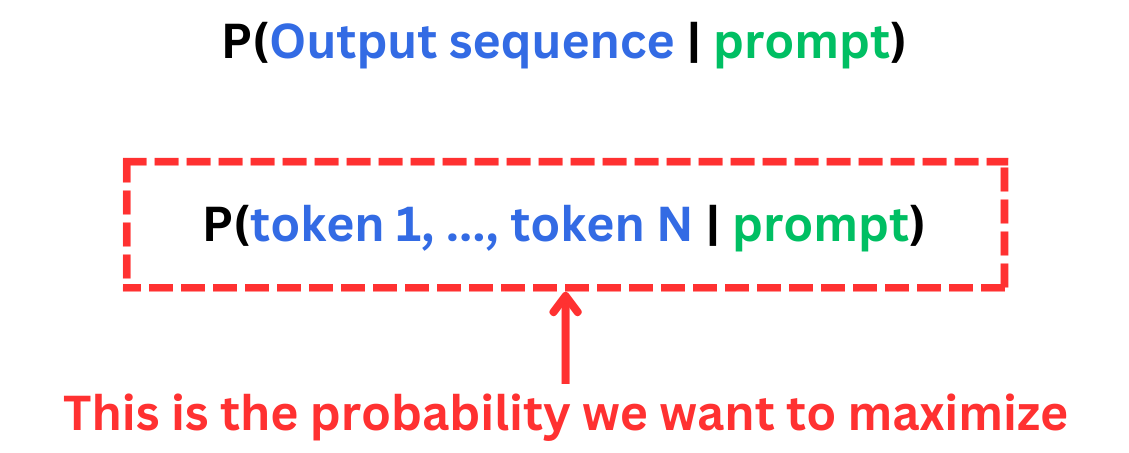
Fortunately, we can compute the probability we care about from the probabilities predicted by the model.

That is important because there could exist a sequence of tokens with a higher probability than the one generated by the greedy search.

Finding the best sequence is an NP-hard problem, but we can simplify the problem by using a heuristic approach. At each step of the decoding process, we assess multiple candidates, and we use the beam width hyperparameter to keep the top best sequences.
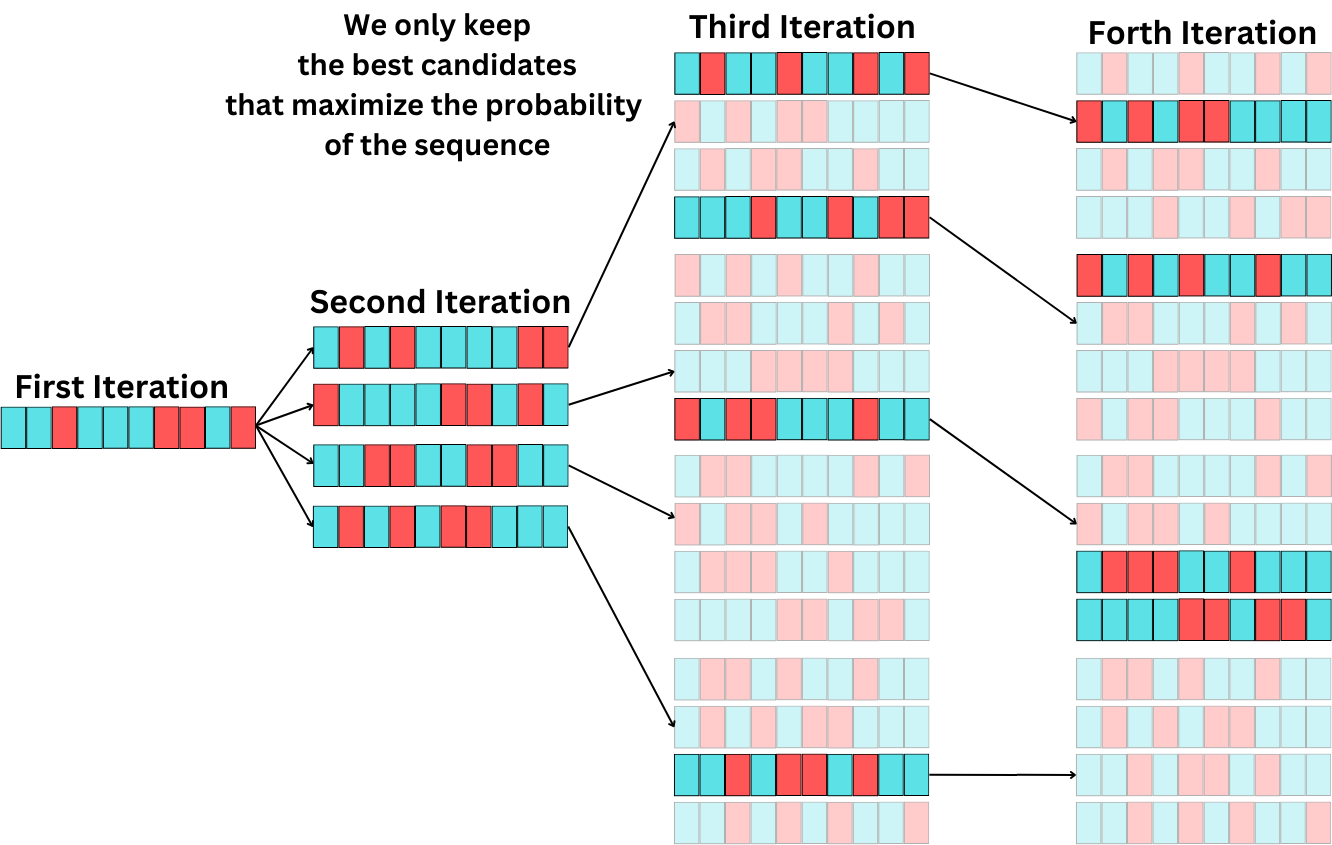
We iterate this process for the N tokens we need to decode, and we keep only the sequence with the highest probability.

Beam search has a few advantages:
- Balance Between Quality and Efficiency
- Flexibility through Beam Width
- Good for Long Sequences
- Useful in Structured Prediction Tasks
- Can be combined with Multinomial sampling
And a few problems:
- Suboptimal Solutions
- Computational Cost
- Length Bias
- Lack of Diversity
- Heuristic Nature
- End-of-Sequence Prediction
2 comments