The Byte Pair Encoding Strategy
The Byte Pair Encoding strategy is the tokenizing strategy used in most modern LLMs. Let’s see an example:
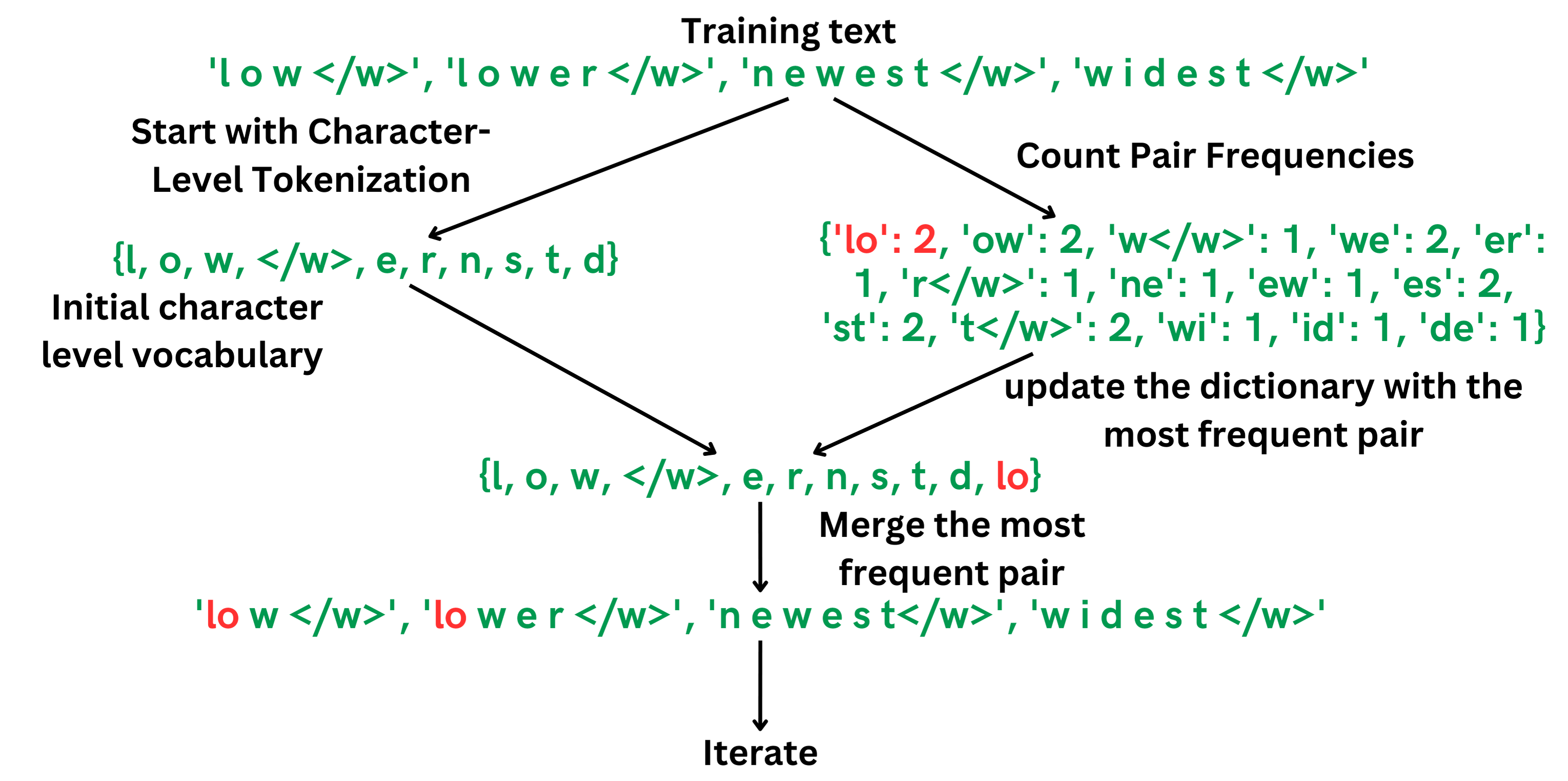
Let’s look at the second iteration:
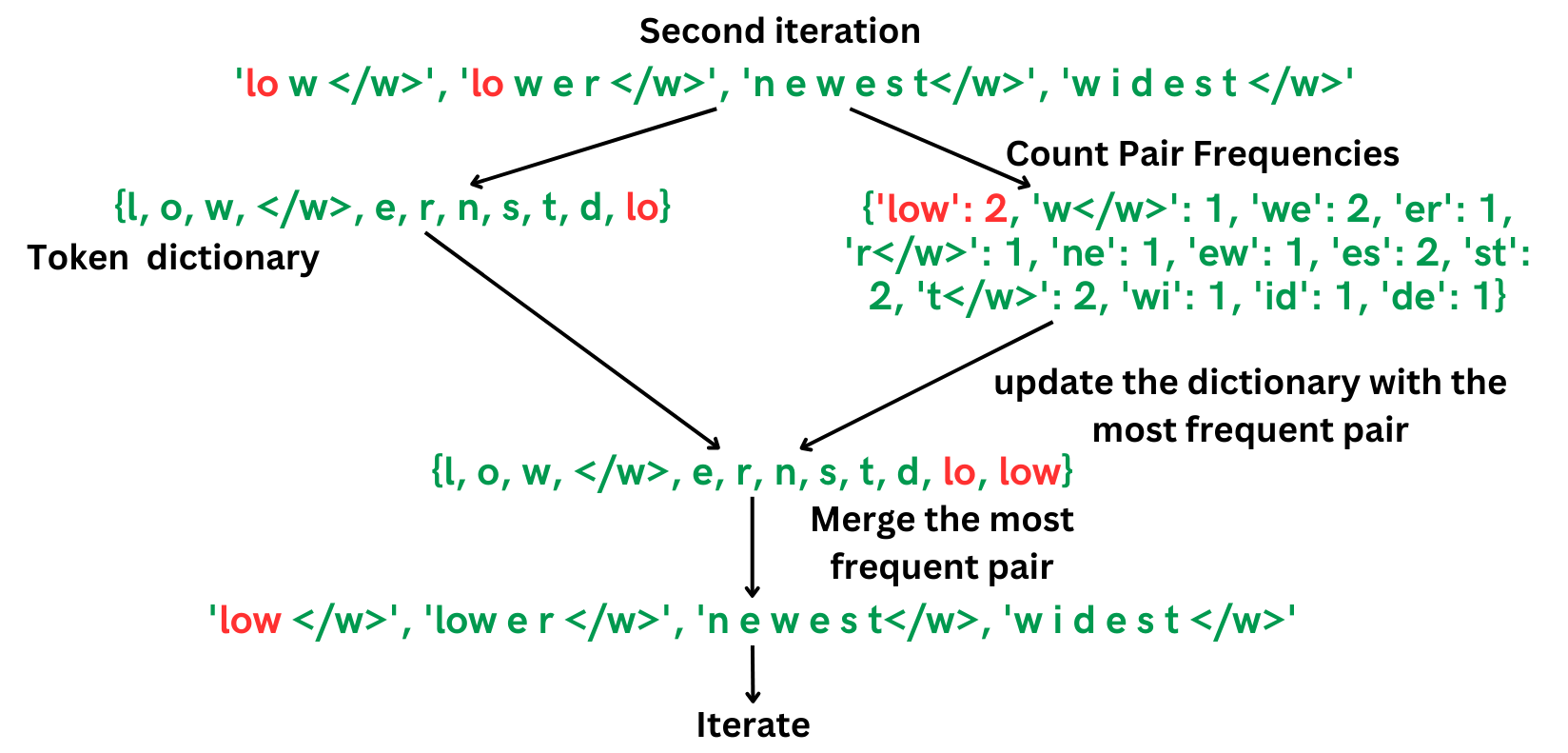
We can iterate this process as many times as we need:

To summarize:
- Start with Character-Level Tokenization
- Count Pair Frequencies
- Merge the Most Frequent Pair
- Repeat the Process
- Finalize the Vocabulary
- Tokenization of New Text
To search tokens in the resulting dictionary, we just search the longest substring in each of the words of a new input sentence:
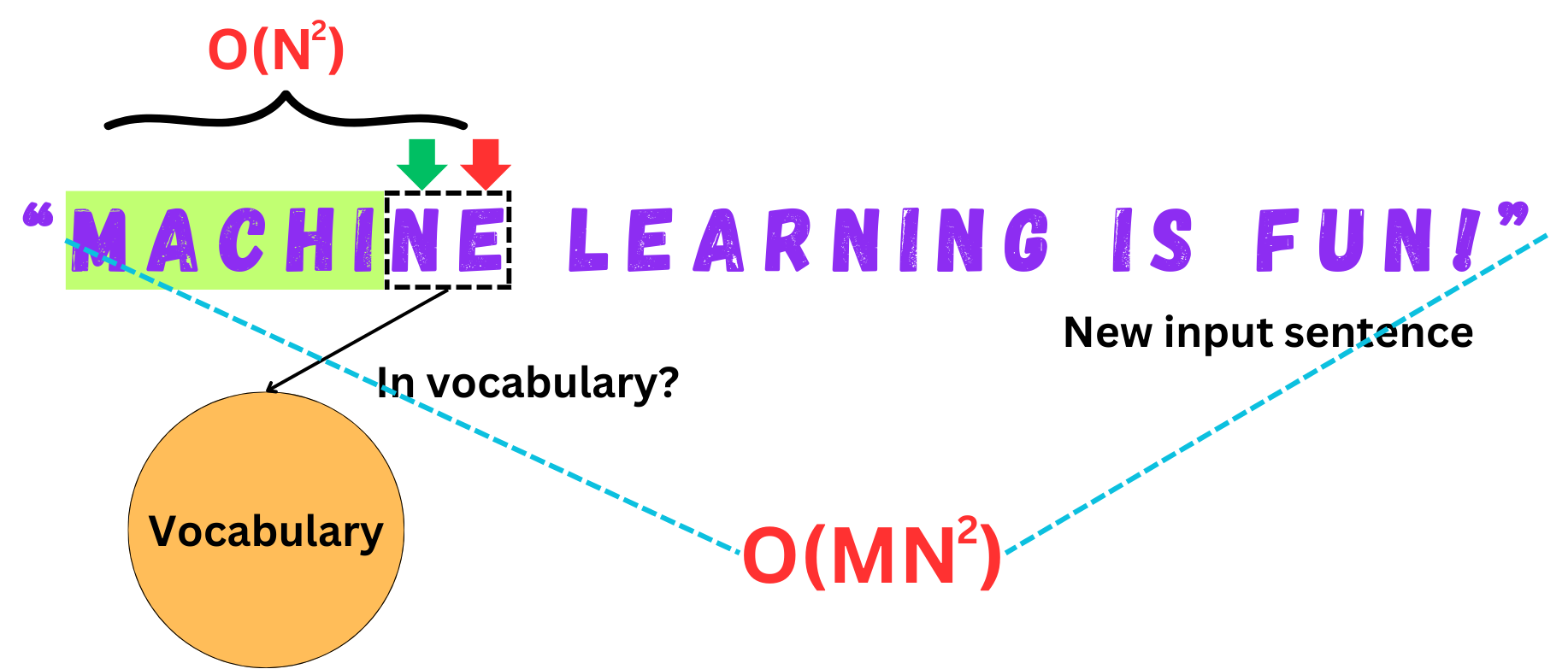
If N is the average number of characters in a word and M is the average number of words in an input sequence, the time complexity of the tokenization process is O(MN2).
0 comments