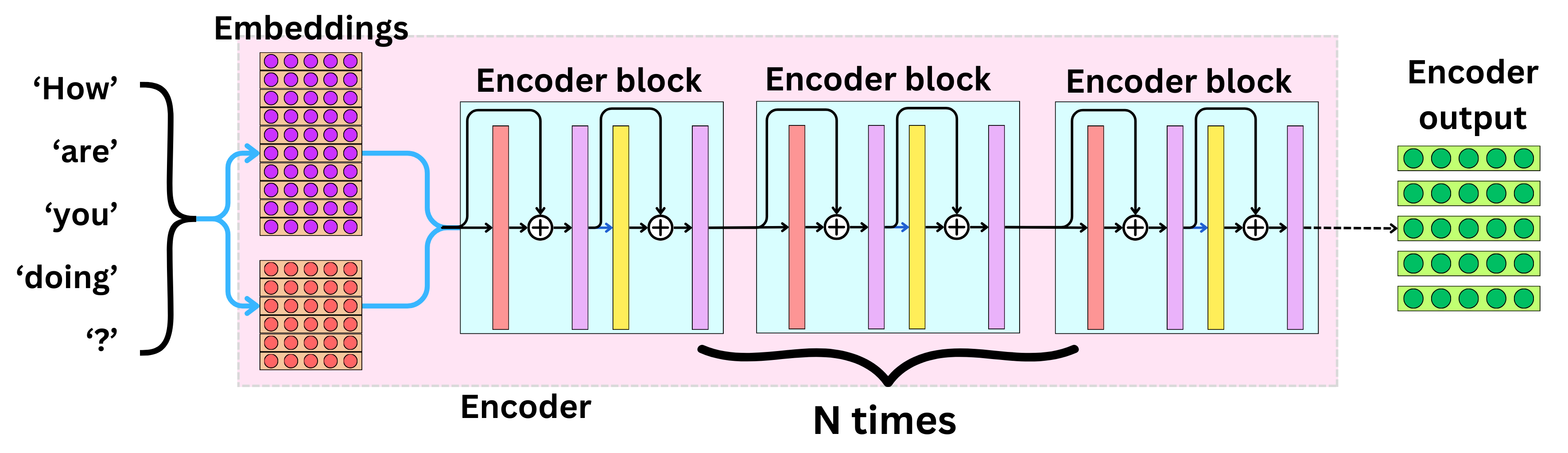
The Encoder
The encoder block is composed of a multi-head attention layer, a position-wise feed-forward network, and two-layer normalization.

The layer normalization allows us to keep the values of the hidden states from becoming too large or too small.

The attention layer allows to learn complex relationships between the hidden states, whereas the position-wise feed-forward network allows to learn complex relationships between the different elements within each vector.

The encoder is just the token embedding and the position embedding followed by multiple encoder blocks.
0 comments